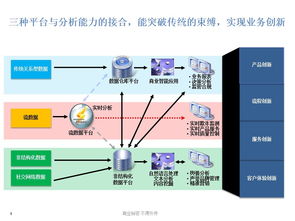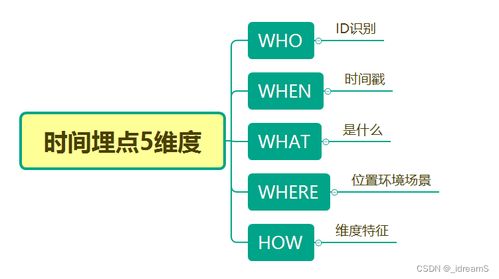
在当今数据驱动的业务环境中,埋点数据处理服务扮演着至关重要的角色。它不仅是连接用户行为与业务决策的桥梁,更是实现精细化运营、产品优化和用户体验提升的基础。本文将系统性地解析埋点数据处理服务的核心概念、流程架构、技术挑战以及最佳实践。
一、埋点数据的核心价值
埋点,通常指在应用程序或网站中预先植入代码,用于采集用户在特定交互节点(如点击按钮、浏览页面、完成交易等)产生的行为数据。这些原始数据是理解用户行为模式、验证产品假设、评估功能效果的核心原料。有效的埋点数据处理服务能够将海量、杂乱无章的原始日志,转化为结构清晰、可信度高、可供分析的标准化数据。
二、数据处理服务的核心流程
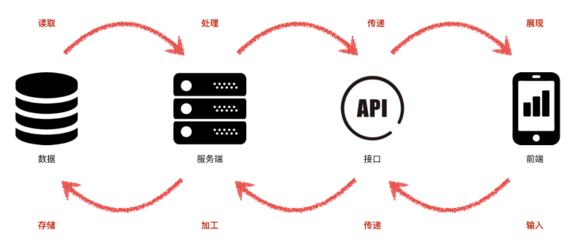
一个完整的埋点数据处理服务通常遵循一个标准化的数据流水线(Data Pipeline):
- 数据采集与上报:客户端(Web、App、小程序等)按照预设的埋点方案采集事件和属性数据,并通过网络协议(如HTTP/HTTPS)实时或批量上报到数据接收服务器(通常称为日志服务器或收集器)。
- 数据接收与缓冲:服务端接收来自各端的数据流,进行初步的合法性校验(如格式检查),并将数据写入高吞吐量的消息队列(如Kafka)或日志文件中,作为原始数据存储,起到缓冲和削峰填谷的作用。
- 数据解析与清洗:这是数据处理的核心环节。服务从缓冲队列中消费原始数据,进行:
- 解析:将JSON、Protocol Buffers等序列化数据还原为结构化的字段。
- 清洗:过滤无效数据(如格式错误、测试数据)、去重、修正错误(如补全缺失的字段、格式化时间戳)。
- 标准化:统一不同来源或版本的数据格式,确保字段命名、值域范围的一致性。
- 数据丰富与关联:为了提升数据价值,服务会将清洗后的数据与其他数据源进行关联和丰富,例如:
- 关联用户画像信息(用户ID、 demographics)。
- 关联设备与网络信息(通过IP解析地理位置、设备型号)。
- 关联业务上下文(会话信息、订单信息、产品属性)。
- 数据加载与存储:处理后的高质量数据会被加载到适合下游使用的存储系统中,通常包括:
- 实时数仓/流处理:如Apache Flink处理的实时流,用于实时监控、预警和实时推荐。
- 离线数仓:如存储在HDFS或云对象存储中,通过Hive/Spark进行T+1的离线分析。
- OLAP数据库:如ClickHouse、Doris或云上分析服务,支持对海量数据的快速即席查询和BI报表生成。
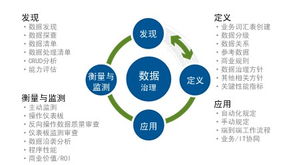
- 数据质量监控与治理:贯穿整个流程,通过监控关键指标(如数据量波动、延迟、错误率、字段填充率)来保障数据质量。建立数据血缘、元数据管理,确保数据的可追溯性和可信度。
三、面临的主要技术挑战
- 高并发与高吞吐:面对海量用户和频繁的交互,系统需具备处理每秒数万甚至数百万事件的能力。
- 低延迟与实时性:部分业务场景(如反欺诈、实时推荐)要求数据处理延迟在秒级甚至毫秒级。
- 数据一致性保障:确保数据不丢失、不重复,尤其是在分布式系统中保证Exactly-Once语义是一大挑战。
- 灵活性与扩展性:业务需求变化快,埋点方案频繁迭代,数据处理逻辑需要能灵活配置和快速扩展。
- 成本与效率:海量数据的存储与计算成本高昂,需要在架构设计和资源调度上不断优化。
四、最佳实践与趋势
- 规范化埋点设计:采用业界成熟的埋点模型(如事件-实体模型),在源头保证数据的规范性。
- 流批一体架构:利用Flink等现代计算引擎,构建统一的流批处理逻辑,简化架构,保障数据口径一致。
- 可观测性建设:建立完善的数据处理链路监控、报警和根因分析体系,快速定位问题。
- 自动化与平台化:提供自助化的埋点管理、数据处理任务配置与调度平台,提升数据团队的效率。
- 隐私与安全合规:在数据处理全链路中,严格遵循GDPR、CCPA等数据隐私法规,对敏感数据进行脱敏、加密和访问控制。
###
埋点数据处理服务是现代数据基础设施的“中枢神经系统”。它决定了企业能否将原始的用户行为“矿石”高效、精准地冶炼成驱动业务增长的“数据燃料”。构建一个稳定、高效、灵活且合规的数据处理服务,是任何一家致力于数据驱动决策的企业必须夯实的基石。随着云原生、Serverless和AI技术的融合,未来的数据处理服务将朝着更智能、更自治、更低成本的方向持续演进。